Over the last year I have had the pleasure to work with Airslie Ltd, a UK-based medical informatics company, and King's College Hospital (NHS Foundation Trust) to rewrite and extended their clinical observations and assessments system, Wardware®. Wardware enables the entry, analysis and display of Early Warning Scores and other patient datasets for clinical use locally or remotely on mobile and desktop computers. The application was originally built using PHP, sans framework, and the company who originally authored the application, Airslie, was motivated to rewrite it using an application framework. Their chosen framework was Ruby on Rails and they approached me to lead the development effort.

Desktop and Mobile views of Patient Chart
Facilitating the National Early Warning Score (NEWS)
The pivotal component of Wardware is the Observations and Assessments module. This module implements a number of assessments, including a key assessment for patient health, the - National Early Warning Score (NEWS). Early Warning Scores (EWS) are used to "quickly determine the degree of illness of a patient". This is determined by the scoring of physiological parameters such as temperature, heart rate and blood pressure. The total score assigns a patient to a risk category and the appropriate response, based on a predefined protocol, is carried out.
Physiological parameters are recorded using a mobile device, the MioCare Tablet, at the patient's bedside. The patient's charts, such as the NEWS chart can be viewed either on a desktop or the mobile device. The application has been developed using a Responsive front-end framework, allowing a single UI to be used for both desktop and mobile devices.
The Observations and Assessments module is designed to be extended. It is a platform for implementing other assessments by simply configuring the physiological parameters and the assessment's calculator. Beyond NEWS, the Wardware installation at King's College Hospital is currently configured for:
Key assessments summarized in configurable Wardboards and Charts
Key assessments scores for patients such as NEWS along with assessment frequencies and due times are summarized on the Wardboard.
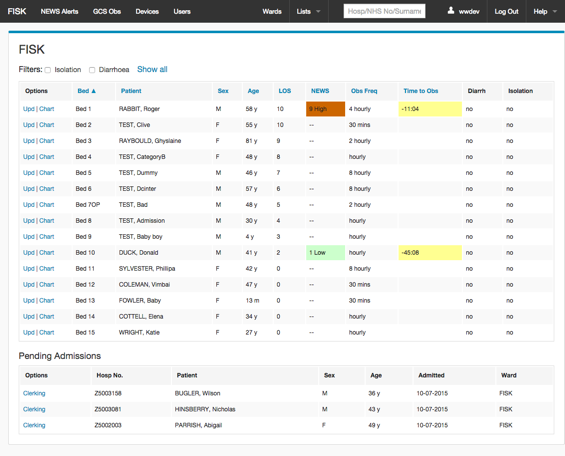
Wardboard summarizing current admissions for a specific ward.
Assessments with a specific threshold (e.g. a NEWS score greater than two) are also summarized at a ward and site-wide level.
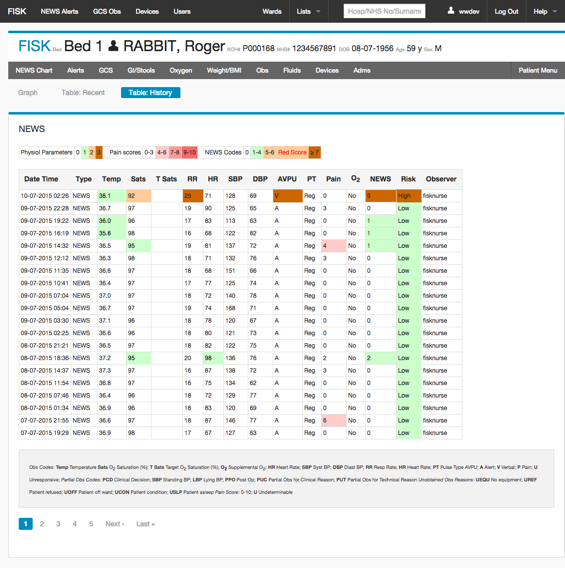
Observation and Assessment Charts are presented in three formats:
1. Graphical
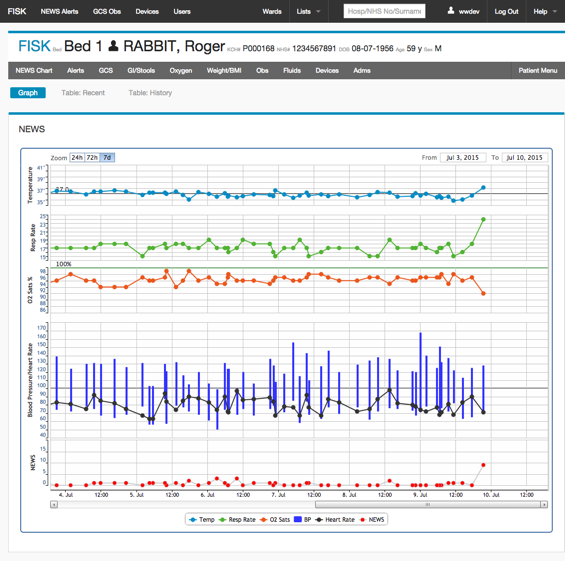
2. Tabular with the most recent 20 observations

3. Tabular with all historical patient data paginated
A range of modules supporting a patient's tracking and analysis requirements
Wardware doesn't just support observations and assessments, it supports various tracking and analysis requirements to monitor a patient. Briefly these include:
- Oxygen Delivery Management, including the tracking of patient oxygen concentration targets
- Response Management, recording responses to assessments such as NEWS
- Device Management for surgical and urinary devices. Device Management tracks insertion and removal of devices for a patient, including the recording of complications
- Diarrhoea Management integrated with Stools based on the Bristol Stool type
- Blood Products Management (e.g. RBC, FFP, Platelets)
- Fluid Management tracking patient's fluid balance and reporting
Wardware's Admissions module completes the admission process by assigning patients to a bed in their designated ward. Admissions for wards are automatically populated through a custom module integrating Wardware with KCH's Patient Information Management System (PIMS) using the Health Level-7 (HL7) messaging format, "a set of international standards for transfer of clinical and administrative data between software applications".
And there's a lot more
There is a lot more detail I can go into, but this post is long enough. Here are some facets that I'll highlight here:
- Authentication and Authorization Management
- Patient search via bar code scan from admission bracelet
- Business Continuity Programme (offline storage of patient obs)
Domain Modeling Challenges
In future blog posts I will discuss some of the interesting domain modelling challenges of this project and how I leveraged Martin Fowler's Analysis Patterns. His patterns for observations and measurements is based on his work with the Cosmos Clinical Process Model for the UK National Health Service.
